
The 1 Trillion Token Context Window
From 4K to 1M to 1B to 1T:
If you want to understand where AI is going, let’s stop staring at “IQ” benchmarks for a minute and look at memory.
An A.I. model’s context window is its working memory: how much information it can hold in mind at once while reasoning. It’s measured in tokens (roughly word chunks, though tokenization varies by language and content).
When context windows expand, the category of software expands. This is the same pattern we lived through in the PC era when RAM and storage went from kilobytes to megabytes to gigabytes to terabytes to petabytes. Bigger memory didn’t just make the old apps faster, it created entirely new apps.
We’re watching that happen again, except this time the “app” is “intelligence”.
What The Hell Is A Context Window?
A context window isn’t hard drive “storage.” It’s closer to a computer’s RAM.
When you send a prompt, the system tokenizes it (breaks text into token units like below), then a transformer model (more on that here), processes the full sequence to predict the next token.
Under the hood, transformers use self-attention: each token can look at (attend to) other tokens to decide what matters for the next step. During generation, the model keeps a running internal cache of what it has already computed for prior tokens (often called the KV cache, because it stores “keys” and “values” for attention).
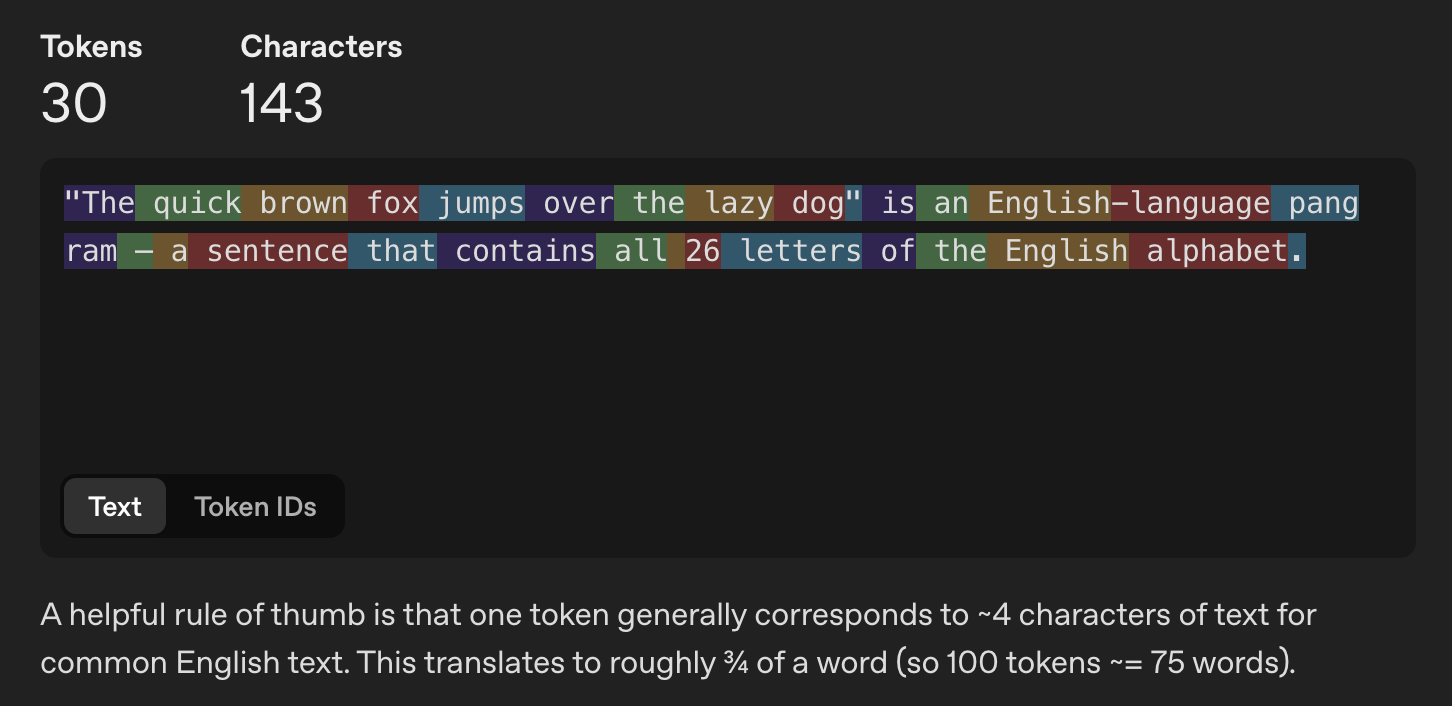
That cache grows with every additional token. So longer context is expensive in two ways:
Memory (VRAM/RAM): the KV cache scales roughly with context length × layers × hidden size.
Compute/time: attention and related operations get heavier as the sequence gets longer, even with modern optimizations.
How model size (parameters) relates to context length
Model parameters are the fixed weights (the “brain size”). They don’t automatically give you a bigger context window. A smaller model can be built with a huge context window, and a massive model can ship with a smaller one.
But model size heavily affects the cost of long context:
Bigger models typically have more layers and larger hidden dimensions, so each token consumes more KV cache memory.
That means at a given hardware budget, there’s a tradeoff: bigger model or longer context (unless you scale hardware or distribute inference).
Bigger models often do better at long-context reasoning if they were trained for it—they’re better at “needle in a haystack” retrieval, and they can maintain coherence across more material.
How and why newer models get bigger context windows
Vendors have been pushing context limits upward because three things improved at once:
Training methods: models are increasingly trained or fine-tuned on longer sequences so they don’t fall apart when you hand them book-scale inputs.
Position handling: transformers need a way to represent “where” a token sits in a sequence (positional encoding). Newer approaches (and extensions to existing ones, like scaling/adjusting rotary position methods) make it more reliable to generalize beyond the lengths seen early in training.
Systems engineering: better attention kernels (faster GPU implementations), smarter caching, chunking, and memory hierarchies make long context economically viable.
The key idea: “a 1M context model” is rarely doing one naive, quadratic attention pass over a million tokens like it’s 2017. It’s typically a stack of innovations—efficient attention, caching, longer-sequence training, and increasingly hierarchical memory (hot/warm/cold) so the system can reach a massive corpus without needing every byte in the active window at once.
Where Context Windows Started in 2022
In 2022, the mainstream experience was a few thousand tokens.
The GPT‑3.5 model that powered the launch of ChatGPT is commonly cited at 4,096 tokens of context. On the order of a handful of pages, not a library.
That shaped how we used AI:
short prompts
short conversations
“paste a paragraph, get an answer”
summaries and rewrites
small snippets of code
You could feel the ceiling. The model wasn’t “forgetting” because it was lazy. It was forgetting because it literally couldn’t keep the whole thread in memory.
That limitation is why RAG (retrieval‑augmented generation) and vector search exploded.
For a couple years, the “correct” architecture looked like this: keep your knowledge outside the model (docs, wikis, tickets, policies, code), embed it into a vector database, retrieve the top‑K chunks relevant to the user’s question, then inject those chunks into the prompt so the model could answer as if it had the memory. It is a clever workaround for tiny context windows and it helped ground answers in source material.
But then something happened: One million‑token context windows showed up in real products. Suddenly, for many internal use cases, you can skip brittle chunking and retrieval and just drop the whole handbook (or a big slice of the repo, looking at you Cursor) into the prompt . RAG doesn’t disappear as it’s still essential for freshness, access control, and anything truly massive. But long context turns it from “mandatory plumbing” into “an optimization lever.”
Where Are We Now in Early 2026
Today, long context is real — and it’s arriving in layers, with each of the leading companies shipping models that have larger context windows.
OpenAI GPT-4.1: 1,047,576 tokens of context.
Anthropic Claude Opus 4.6: 1M token context window in beta.
Google Gemini 3: A 1 million-token context window.
To make that scale visceral: a 1M window can fit book-scale inputs in a single request. This is a phase change.
The PC Analogy
In the 2000s, memory growth created a ladder:
KB → MB: basic documents, simple apps, floppy discs
MB → GB: browsers, rich media, “do everything” desktop software, CD ROM’s
GB → TB: personal photo and video libraries, local archives, USB flash drives, external hard drives, search over your stuff
TB → PB: data warehouses, analytics, machine learning pipelines

AI context windows are climbing the same ladder:
4K tokens (2022): “single document” intelligence
128K to 200K: “small library” intelligence
1M to 2M: “department, codebase, case file” intelligence
10M+ (research direction): “organization” intelligence
1B (the next horizon): “enterprise memory” intelligence
1T (the thought experiment): “civilization‑scale” intelligence?
Bigger context won’t just make the same chatbot better. It unlocks new kinds of software.
What Becomes Possible As Context Grows
1) Whole‑artifact reasoning replaces snippet reasoning
With small context, AI is a smart autocomplete that you constantly feed.
With million‑token context, AI can take in:
a meaningful chunk of a codebase
a full contract set for a deal
a complete customer history
meeting transcripts plus emails plus docs behind a project
The difference is coherence. The model stops inventing structure because it can actually see structure.
2) The model becomes a system, not a chat
Bigger context windows are the foundation for agents that can plan multi‑step work without losing the plot. When the agent can keep the goal, constraints, prior attempts, and the source materials all in memory, it stops thrashing.
This is when AI stops feeling like a conversation and starts feeling like an operating system.
3) In‑context learning becomes practical
When you can fit a full playbook inside the prompt (SOPs, examples, edge cases), the model can learn how your organization works on the fly without fine‑tuning.
4) Search and analytics collapse into one interface
At small context, you search for info, then ask the model.
At huge context, the model can consume the corpus and answer with comparisons and cross‑document reasoning in one go. This is why long context is a direct threat to the traditional “search box → ten blue search result links → manual synthesis” workflow.
5) Personal and organizational memory becomes real (and controversial)
A million tokens is enough for “a lot of you,” but not “all of you.”
A billion tokens is where the idea of durable, high‑fidelity personal and company memory starts to feel inevitable.
A trillion tokens is where it gets existential.
The Billion‑Token Era
A billion tokens is not a slightly bigger prompt. It’s a different class of system.
The closest biological analogy in this era is the human brain. We have ~86B neurons and on the order of ~100T synapses. But the real lesson isn’t raw “storage”; it’s actually architecture. Humans have a tight working-memory bottleneck (a few chunks), yet we feel limitless because we retrieve the right memory at the right moment.
That’s the same direction AI is moving: a compact reasoning engine paired with huge reachable memory and tool access. In that world, “context window” stops meaning “one giant prompt” and starts meaning “how much of reality the system can reliably bring into the room at the right time.”
Think about what fits inside “enterprise memory”:
Years of email and meeting transcripts
Slack and Teams history
Whole CRM, ticketing, and support logs
Contracts, policies, and internal wikis
Code, specs, PRDs, incidents, and postmortems
Every customer call summary and renewal thread
At this scale, the model can stop being a tool you consult and start being a brain you run.
What Software Looks Like at 1B Tokens:
1) The company gets a living institutional memory.
Not a wiki. Not a search engine. A memory that can answer questions like:
“When have we tried this before and why did it fail?”
“Which customers asked for this, and what did we promise them?”
“What security exceptions did we grant, and what was the rationale?”
2) Compliance becomes continuous.
Instead of preparing for audits, the system is always checking.
It can track policy drift, flag risky language, surface missing approvals, and maintain provenance for why decisions were made.
3) Strategy becomes simulation.
When you can load the company’s full history, you can run counterfactuals.
“What if we raised pricing last year?” “What if we restructured the funnel?” “What if we fired that product line earlier?”
These won’t be perfect forecasts, but they will be grounded in far more evidence than a human can hold in mind at one time.
4) The agent stops being a worker and becomes a manager.
With enough memory, an agent can coordinate other agents with stable direction. It can maintain long‑running objectives across months of work without constantly being re‑trained by human reminders.
What This Does To Work
At 1B tokens, the definition of “knowledge work” shifts. The bottleneck moves from information retrieval to judgment, taste, ethics, and relationships.
The winning teams won’t be the ones who “use AI.” They’ll be the ones who build the cleanest, most consentful memory for AI to run on.
The Trillion Token Horizon
Sam Altman has described a kind of north‑star architecture for AI: a relatively compact reasoning engine paired with extreme memory and effectively unlimited tool access.
“It can run ridiculously fast and 1 trillion tokens of context and access to every tool you can possibly imagine.”
- Sam Altman
This framing matters because it flips the obsession from stuffing the model with knowledge to building systems that can think, remember, and reach.
1T tokens of context become the working set for identity, history, constraints, and long‑range coherence.
Unlimited tool access becomes the bridge to the real world: search, databases, code execution, simulations, CRMs, inboxes, payments, and other agents.
The model itself becomes the reasoning engine orchestrating memory and tools, not the place where everything lives.
A trillion tokens is where the scope moves beyond a single enterprise. A trillion‑token system could plausibly reason across:
An industry’s contracts, norms, and market structure
Entire ecosystems of company interactions
Multi‑institution deal networks
Massive multimodal archives (text, audio, video, code)
This is the “civilization graph” direction: not just remembering your company, but understanding the web of incentives and history around it.
What software Looks Like At 1T Tokens:
1) Cross‑organization intelligence becomes normal.
Today, every org reinvents the wheel because its memory is locked inside its own tools.
At 1T scale, you get systems that can map patterns across thousands of organizations, not as a static report, but as a reasoning engine.
2) Deals become computed.
For high‑stakes workflows like fundraising, partnerships, M&A, procurement, hiring, and public grants, the limiting factor is usually context.
A trillion tokens means the agent can carry the full history: people, incentives, prior negotiations, market comps, and every clause ever argued.
That changes negotiation itself. Not because it “wins,” but because it stops missing obvious things.
3) Education flips from content to guided cognition.
If a system can keep the full canon plus your learning history in memory, education becomes adaptive reasoning rather than consumption.
The Hard Truth: 1B and 1T Won’t Be A Single Giant Prompt
Naively scaling a transformer to a billion or a trillion tokens is computationally brutal.
So the real path is a memory hierarchy, exactly like computer architecture:
Hot memory: small, fast context for what you’re doing right now
Warm memory: cached context you reuse often
Cold memory: massive external stores the model can retrieve from
Compression: summaries, embeddings, structured representations, and learned retrieval
In practice, “1B token context” and “1T token context” will mean something like: A system that can reliably access and reason over a billion or a trillion tokens worth of reachable memory, even if it is not attending to all of it at once. That’s still revolutionary.
In 2022, context windows made AI feel like a clever assistant you had to babysit.
In 2026, million‑token context makes AI feel like it can actually hold the whole problem.
A billion tokens is where AI starts to feel like a true institutional brain.
A trillion tokens is where AI starts to feel like a new layer of civilization.
The future is not “bigger prompts.” The future is better LLMs + hierarchical memory + retrieval + caching + agents. That stack is to the 2020’s what RAM + hard drive storage + operating systems + internet search was to the 2000s.
Notes and sources:
OpenAI GPT-4.1 announcement: https://openai.com/index/gpt-4-1/
OpenAI model docs (GPT-4.1 context size): https://platform.openai.com/docs/models/gpt-4.1
Anthropic Claude Opus 4.6 announcement: https://www.anthropic.com/news/claude-opus-4-6
OpenAI GPT-5.3-Codex announcement: https://openai.com/index/introducing-gpt-5-3-codex/
OpenAI model docs (GPT-5-Codex 400K context window): https://platform.openai.com/docs/models/gpt-5-codex
Google Gemini 3 announcement (1M context): https://blog.google/products-and-platforms/products/gemini/gemini-3/
Google Developers Blog (Gemini 1.5 Pro 2M context): https://developers.googleblog.com/en/new-features-for-the-gemini-api-and-google-ai-studio/
Google Vertex AI docs (Gemini 1.5 Pro 2M context): https://docs.cloud.google.com/vertex-ai/generative-ai/docs/long-context
IBM explainer on context windows (includes GPT-3.5 4,096 tokens reference): https://www.ibm.com/think/topics/context-window
IBM explainer on RAG: https://www.ibm.com/think/topics/retrieval-augmented-generation
LangChain: Deconstructing RAG: https://www.blog.langchain.com/deconstructing-rag/
Sam Altman quote context (Snowflake Summit 2025 recap): https://www.constellationr.com/blog-news/insights/openais-enterprise-business-surging-says-altman
Video source (Reddit): https://www.reddit.com/r/accelerate/comments/1prcm4d/sam_altman_the_real_ai_breakthrough_wont_be/
Clip source (X): https://x.com/ai_for_success/status/1930124467558330446